2026
When Errors Can Be Beneficial: A Categorization of Imperfect Rewards for Policy Gradient
Shuning Shang*, Hubert Strauss*, Stanley Wei, Sanjeev Arora, Noam Razin (* equal contribution)
Preprint.
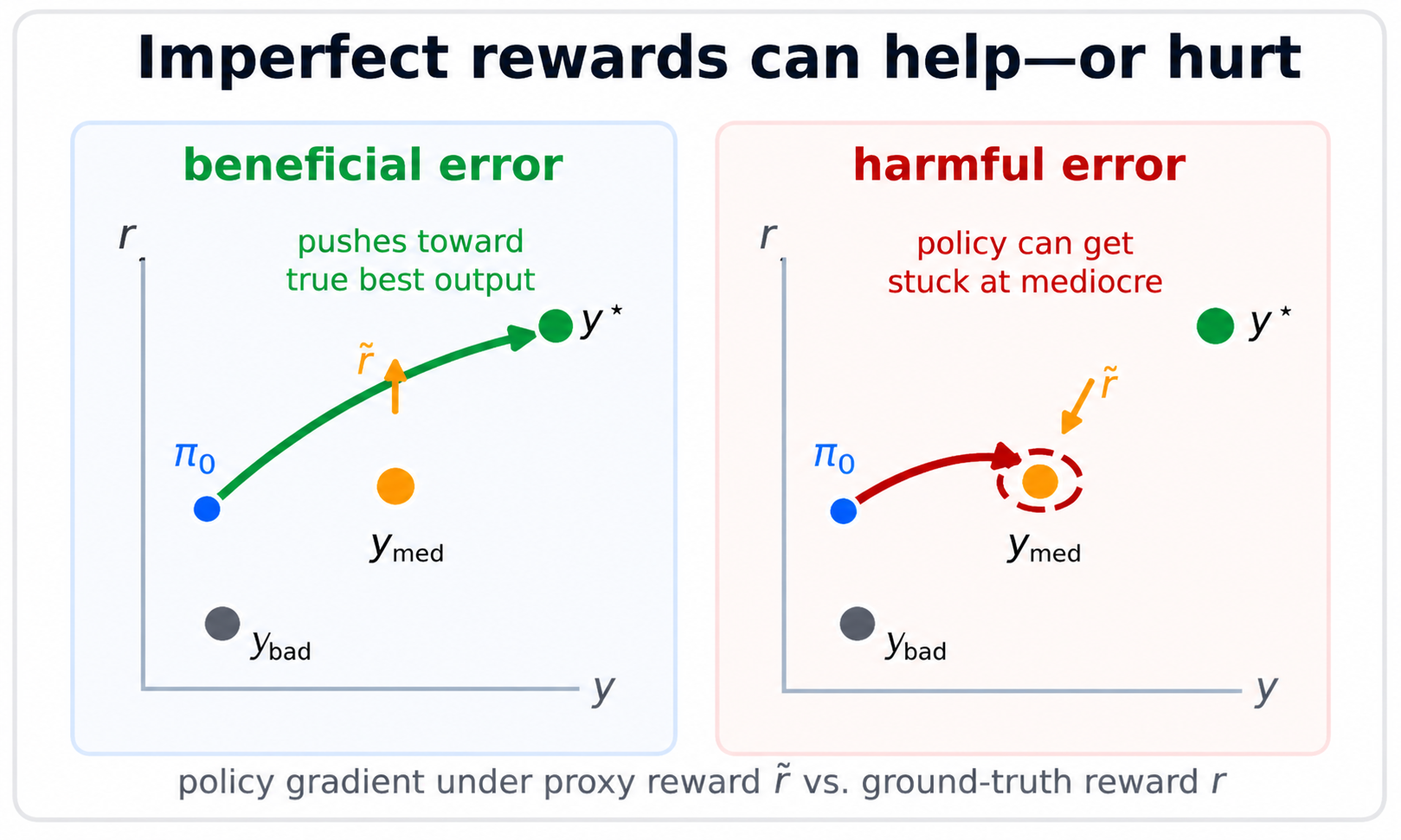
Reinforcement learning for language models often relies on imperfect proxy rewards. While standard reward model metrics treat reward errors as uniformly harmful, we show that their effects depend on the learning dynamics: some errors can trap the policy near mediocre outputs, while others can help it reach higher ground-truth reward. We use this perspective to categorize reward errors, propose harm-aware evaluation metrics for reward models, and discuss implications for reward design in RLHF and verifiable-reward settings.
When Errors Can Be Beneficial: A Categorization of Imperfect Rewards for Policy Gradient
Shuning Shang*, Hubert Strauss*, Stanley Wei, Sanjeev Arora, Noam Razin (* equal contribution)
Preprint.
Reinforcement learning for language models often relies on imperfect proxy rewards. While standard reward model metrics treat reward errors as uniformly harmful, we show that their effects depend on the learning dynamics: some errors can trap the policy near mediocre outputs, while others can help it reach higher ground-truth reward. We use this perspective to categorize reward errors, propose harm-aware evaluation metrics for reward models, and discuss implications for reward design in RLHF and verifiable-reward settings.
2025
Benign Overfitting in Single-Head Attention
Roey Magen*, Shuning Shang*, Zhiwei Xu, Spencer Frei, Wei Hu†, Gal Vardi† (* equal contribution)
Neurips 2025.
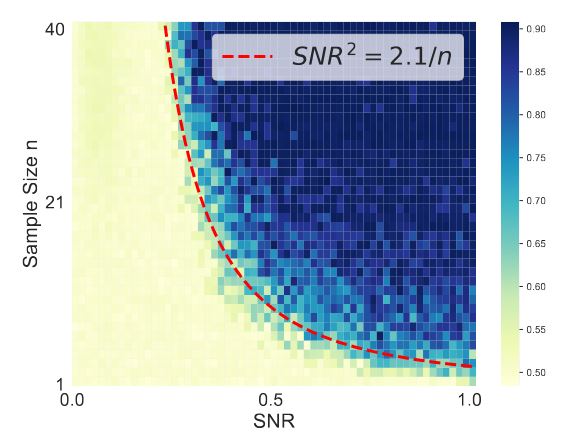
We study benign overfitting in single-head attention, the core of Transformers. We show that under certain conditions, the model can fit noisy training data and still generalize well, even after just two steps of gradient descent. Our results highlight the key role of the signal-to-noise ratio in enabling this behavior.
Benign Overfitting in Single-Head Attention
Roey Magen*, Shuning Shang*, Zhiwei Xu, Spencer Frei, Wei Hu†, Gal Vardi† (* equal contribution)
Neurips 2025.
We study benign overfitting in single-head attention, the core of Transformers. We show that under certain conditions, the model can fit noisy training data and still generalize well, even after just two steps of gradient descent. Our results highlight the key role of the signal-to-noise ratio in enabling this behavior.
2024
Initialization Matters: On the Benign Overfitting of Two-Layer ReLU CNN with Fully Trainable Layers
Shuning Shang, Xuran Meng, Yuan Cao, Difan Zou
Under review.
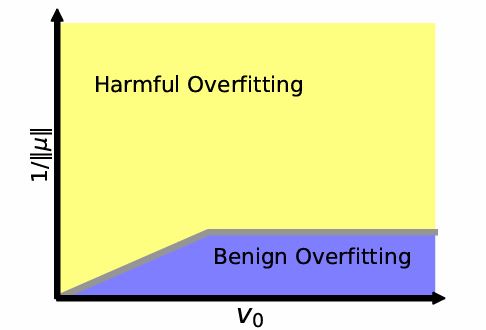
We study benign overfitting in two-layer ReLU CNNs with all layers trained, going beyond prior work that fixes the output layer. We show that the output layer's initialization scale crucially affects training dynamics and generalization. Our analysis provides sharp conditions under which benign overfitting occurs, supported by matching bounds and experiments.
Initialization Matters: On the Benign Overfitting of Two-Layer ReLU CNN with Fully Trainable Layers
Shuning Shang, Xuran Meng, Yuan Cao, Difan Zou
Under review.
We study benign overfitting in two-layer ReLU CNNs with all layers trained, going beyond prior work that fixes the output layer. We show that the output layer's initialization scale crucially affects training dynamics and generalization. Our analysis provides sharp conditions under which benign overfitting occurs, supported by matching bounds and experiments.